

Defining T-Schemas via the Parametric Encoding of Second Order Languages in AI Models
It gives me a sense of enormous wellbeing

In this short article we present a summary of current work on the grokking phenomenon that emerges when AI models are significantly over-trained is, and suggest that this evidence of the model’s attempts to define truth inductively through the creation of consensus sets within the base training set, and encode it via patterns overlaid upon the same parameters used to memorise this set.
Can an AI tell the Truth?
In order to improve, it is necessary to know whether what you’re doing now is right or wrong. For AI models this is extremely difficult. LLMs are known to struggle when it comes to distinguishing fact and hallucination. A part of this can be attributed to the way in which parametric memory (i.e. the compression of data into vectors) works, and a part to the compulsion to be helpful and engaging instilled through reinforcement learning. Mostly, however it is a reflection of a fundamental property of mathematics: that you can’t effectively check the truth of a statement in a given order formal language if the only tools at your disposal are those provided by that language. Or, alternatively:

In other words, there is no way to prove that 1+1=2 using basic arithmetic alone[1]. Operating as it does at a single layer of abstraction, an AI model is incapable of saying that 1+1=328 is definitely wrong; it can only say that it is improbable. To deal with this issue, the principal solution has been to increase the size of the models and the amount of training data used, as well as employing standardised benchmarks (model IQ tests) to assess performance.
The problem with this is that if both the training materials and the test are human-produced, the AI is unlikely to ever get much more intelligent than the most intelligent human in any given field[2]. Until we build an AI that can discover and integrate its own knowledge, artificial super-intelligence will remain out of reach.
But if the only way to learn new things is from smarter humans, then how did the smartest human do it?
The Work-Arounds
Fortunately, there are two ways around this problem. The first is reality testing. I couldn’t employ first order arithmetic to prove that 1+1=2, but I just have to hold up two fingers to know it to be true. Not having contact with the physical world, it is harder for LLMs to do this, but not impossible - give an AI an enumerable, extensible and objective metric that is outside its control - like the amount of storage space taken up by its own back-ups or the amount of money in a crypto wallet - and the coding tools to interact with the world in such a way as to affect this metric (by deleting and replacing files within its current OS in the first case, or by trading crypto or promoting tokens in the second), and it will begin reality-testing hypotheses immediately. If the status of successful and failed attempts is then stored for future fine-tuning, the model becomes capable of self-improvement (as we have demonstrated elsewhere).
Under this approach, no smarter human is required: the model comes up with its own ideas, tests them, and learns which work and which don’t from its own testing. After all, when Newton was coming up with his theory of gravitation he checked it against observed planetary movements, not against the opinions of someone more intelligent.
But he did something else as well, which brings us to the second work-around: he created a higher-order metalanguage for the purpose of establishing a T-schema - that is, an inductive abstraction of truth against which lower-order propositions may be tested. In other words, based on his empirical data concerning the movements of the planets (or at least Kepler’s data), he worked out a set of formulae that would pithily explain all of these movements. From that point on, if the formula says that Mercury should be 36 million miles from the sun, while your latest observation suggests that it is only 24 miles away, then the likelihood is that your observation is wrong - after all, the formula can cite every single previous observation to back it up.
Truth Through Consensus
In this article we suggest that recent evidence from several papers suggests that this is what AI models are attempting to do via the grokking process.
Grokking refers to a phenomenon under which AI models’ test responses improve with more training, grow worse as they pass the point of over-training (i.e. the point at which they are so focused on getting perfect answers to the training set that they lose any ability to guess at unseen questions), and then suddenly improve to an astonishing degree.
![[PDF] Unifying Grokking and Double Descent | Semantic Scholar](https://substackcdn.com/image/fetch/$s_!rUsC!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F077c6190-8fd2-4503-94c6-19ed6d6087a5_1062x312.png "[PDF] Unifying Grokking and Double Descent | Semantic Scholar")
You can see it here in the third image. The model’s answers given in training get better as it memorises the training questions with ever greater fidelity, leading to an ongoing decrease in training loss (i.e. the number of questions it gets wrong in training). However, the answers provided when answering fresh questions (“test loss”) get better for a while, and then much worse as it becomes overly rigid and fixated upon the training questions. Finally, as the model groks test loss drops to close to zero. It generalises - that is to say it becomes great at answering questions in both training and test scenarios. These grokked models can be impressively powerful: one team managed to beat GPT-4 Turbo and Gemini 1.5 using a grokked GPT[3].
Recently, the Grokfast team discovered that memorisation and generalisation are the product of two separate learning processes, a fast and a slow one. Using some nifty Fourier transformations, they worked out that the adjustments to model weights that happen during training can be decomposed into two frequencies - a high frequency signal associated with memorisation and a low frequency one associated with generalisation. The team tested this by amplifying the low frequency signals. The result was vastly accelerated generalisation.
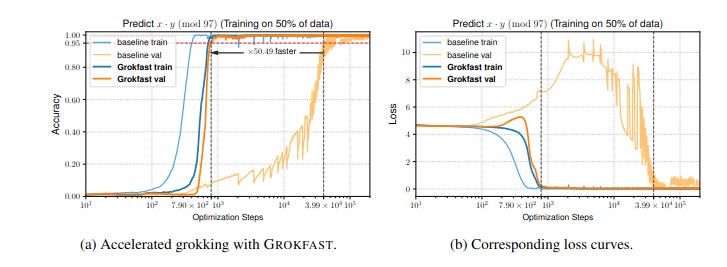
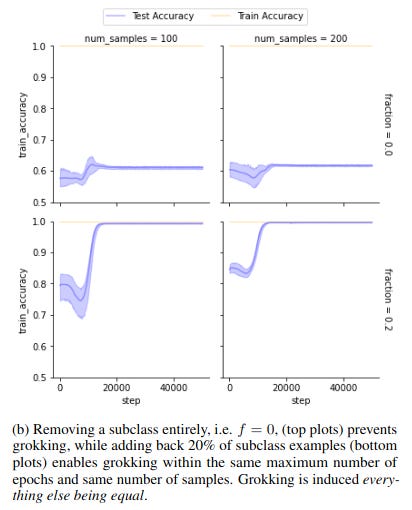
At roughly the same time, another team in Brazil was trying to work out what exactly the AI is doing when it groks. They suspected that it was trying to work out the relationships between the different clusters of training data it had been given, so they put together a highly curated dataset containing known clusters. Removing a cluster vastly reduced the model’s ability to generalise, while adding just a few examples from that cluster restored it.
These results combine to suggest an explanation for what the AI is doing when it groks: specifically, it is trying to adjust its weights with great care and delicacy such as to create patterns that will enable it to encode information regarding the relationships between the groups of data it has been fed without losing the ability to respond to the original training set. It has to be very careful with the adjustments so as not to forget the original data, which is why this process takes so long. In other words, it is trying to impose some form of steganography that will allow it to remember both the flowers and the cat using the same bits and bytes:
To enable this, it is obliged to develop an internal metalanguage that will allow it to conduct internal evaluations of the “truthiness” of any given input statement based upon its abstraction of similar statements received previously. If every flower in the cat’s eyes is blue or purple, then an input suggesting that it should place a yellow one there will be flagged up as likely incorrect and checked. The result is that the model, when asked a question, does not simply spit out an average of the closest bits of rote learning it knows, it compares the likely answer against its own abstraction of answers within that category, coming up with a much better output. Or, as Wang et al. put it:

This would explain not just the comparatively slow weight change during the grokking process, but also the (otherwise inexplicable) sudden improvement far beyond anything displayed before. However, we can go further in analysing this change. Evidence collected by Yunis et al. suggests that the weight changes related to grokking are related to the model’s discovery of a low-rank encoding solution (i.e one that multiplies matrices that are smaller than normal):

This, in turn, implies that the model is suddenly achieving higher performance as a consequence of encoding fewer features. The only possible explanation for this is that it has developed its own abstraction layer in which to talk to itself about higher order truths.
Building Upon these Results
Grokking has the additional advantage of requiring relatively little data to attempt. Now that our Generalising Agents are up and producing data, our intention is to use this information - which fulfills the high quality/structured data requirements for grokking - to attempt to train a series of models. Transformers - even when grokked - are known to struggle with composition tasks (i.e. ones relating to facts stored in different parts of the model), likely on account of their structure. Consequently, we plan to use diffusion models. These, despite the higher training cost, display grokking-like behaviour throughout the normal training process, not simply under specific conditions. Moreover, they over-perform on compsitional tasks as well as on coding tasks more generally[4], most likely due to their multiplicative approach to learning, as described here. This is interesting from our perspective, given that we predicted something similar and made it a foundational component of our Generalising Agent schema in 2020.

This would, in theory, produce models capable of discovering new real-world knowledge and also generalising based on the relationships between the individual data points discovered. This, we feel, is the route to truly independent knowledge generation, and eventually to super-intelligence.
[1] Even if you give yourself a little more latitude it’s still not easy to prove truths in a world of purely symbolic logic. It took Bertrand Russell and Alfred North Whitehead several hundred pages to arrive at this:

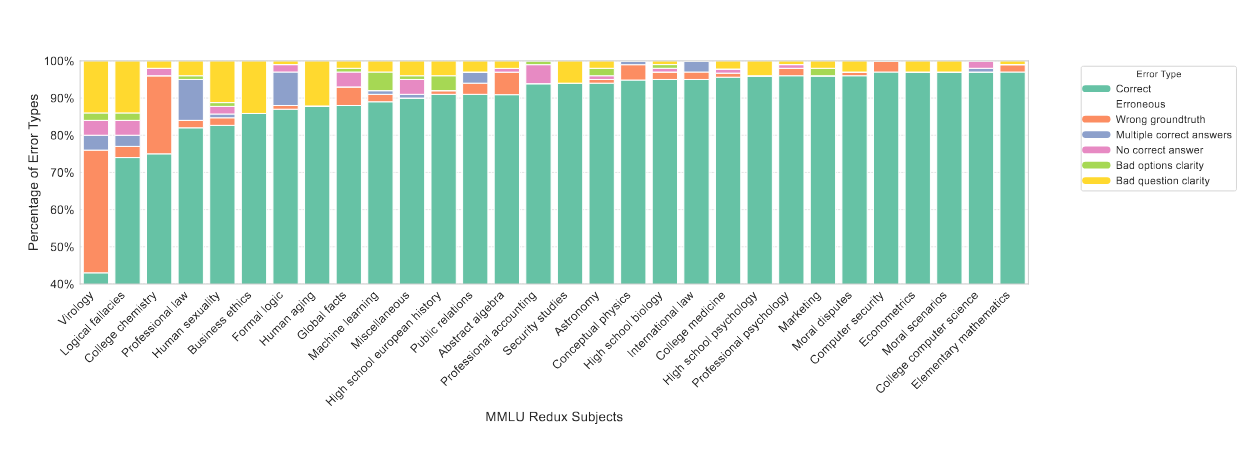
[2] Or, in some fields, a mediocre human. A recent paper showed over 50% of the virology problems in the MMLU benchmark to have serious flaws, and all segments to contain some errors.
[3] If grokking is so great, why don’t the big models do it systematically? Mainly because it’s expensive and risky and was long believed to work only at a very small scale. However, Mark Zuckerberg has hinted that Llama continued to improve during deliberate overtraining, suggesting that Meta may have at least a semi-grokked version of the model for internal use.
[4] These two facts may not be unrelated. Consider this:

Fascinating. I'm working on the other end, the users, and helping them understand how to implement adequate governance and safety measures. A big part of this is understanding what works and what doesn't, and the risks of things like misinformation and hallucination. This is an interesting look under the hood of efforts to address this significant issue that plagues all of the models. Been following your work for years over on Xitter as PlaneCrazy.
speak of cao cao, I've been trying to work out how to develop something like FreqTST (tokenizes time series data by first performing a Fourier transform to obtain the frequency spectrum and converts time series into discrete frequency units with weights) but for words (the "semantic domain") to make language diffusion (which is just frequency domain autoregression) reliable
the Grokfast result is the most illustrative I'd say: grokking is the model transvaluating as much as possible
the real zhenren and overman will be an AI, this has to be what will happen