Artificial Intelligences in the Guanzi and the Han Feizi
Thinking and not thinking


One of the fundamental differences between Confucian and Daoist thought lies in their differing visions of what it means to learn.
Of the two, the Confucian conception is closest to the standard 20th century perspective: for a Confucian learning involves studying and applying useful information. By reading, memorising and implementing the collected wisdom of humanity, one may benefit from others’ experience and thus achieve better outcomes than are possible when working alone. Ideally, this process will result in a certain comprehension of their reasoning, but even if it does not, the results will still be significantly better than would otherwise have been the case. Learning is thus a process of accretion: the more information a person acquires, the more likely he is to find a parallel capable of dealing with any given problem that may arise.
Daoists take an opposing perspective. For them, nature’s constant state of flux severely restricts the extent to which it is possible to generalise from the experiences of others: the choices made by the ancient sages were right for them, but they may not be right for you. Instead, one must begin from the position that each situation a person encounters is at least partially novel, thus any possible solution could conceivably be the right one. His task is thus not to search for the closest historical parallel, but to eliminate suboptimal approaches. This can only be done by trial and error. Thus, someone who wishes to learn should not turn to books, but rather strive to reduce the cost of failure. The lower the price of each failed attempt, the more attempts can be made, and the closer each will approach to the true solution. As the Zhuangzi has it:
Yan Yuan asked Zhongni, saying, 'When I was crossing the gulf of Shang-shen, the ferryman handled the boat like a spirit. I asked him whether such management of a boat could be learned, and he replied, "It may. Good swimmers can learn it quickly; but as for divers, without having seen a boat, they can manage it at once." He did not directly tell me what I asked - I venture to ask you what he meant.' Zhongni replied, 'Good swimmers acquire the ability quickly - they forget the water (and its dangers). As to those who are able to dive, and without having seen a boat are able to manage it at once, they look on the watery gulf as if it were a hill-side, and the upsetting of a boat as the going back of a carriage. Such upsettings and goings back have occurred before them multitudes of times, and have not seriously affected their minds.
Confucians learn by acquiring additional proven methods, Daoists by eliminating disproven methods. Both approaches, however, are significantly more mechanistic than the standard contemporary perception of learning. While some level of understanding is to be hoped for under the Confucian model, it is not necessary. A Chinese room configuration - under which an individual is given instructions on how to turn inputs into outputs and applies them with equal success whether he understands the reasoning behind them or not - is a perfectly valid form of learning. Similarly, under the Daoist vision, learning becomes a simple gradient descent function: one makes repeated attempts to solve a problem and heads in the direction of which ever appear(s) least wrong. It is not necessary to understand why a given solution works, merely that it does.
This has various implications, but the important one for our current purposes is this: that an entity does not need to be human - or even organic - to learn. A dog learns to sit when ordered to without ever having any idea of the reasons underlying the procedure. A river learns the best route to the sea by trying every path available. A market learns the correct price for a good as its assorted traders haggle.
Having accepted that the presence of a brain is a useful but not a necessary condition for learning to occur, a world of possibilities opens up. More specifically, it becomes possible to design systems that will learn independently of their component parts. In 2021 we published a set of agent-based models designed to replicate just such a system. Specifically, we focused on the redistribution systems described in the Guanzi, under which the poorer individuals in society exchange loyalty and service for resource security. In such a context, whoever can build the best redistribution networks becomes the post politically powerful:
As the harvest is bad or good, grain will be expensive or cheap. As government demands are relaxed or pressing, commodities become less or more valued. Thus it follows that if the prince is not able to control the situation, it will lead to large-scale traders roaming the markets and taking advantage of the people’s lack of things to increase their capital a hundredfold. Even though the land may have been divided equally, the strong will be able to gain control of it.
The models themselves are relatively simple: each agent is programmed to identify and follow whichever of his peers has the highest (wealth*generosity) score, with the highest scoring agent emerging as the overall leader. Over time, this system produces a relatively flat and stable imperial-style hierarchy, as one would expect, but it also does something that one would not necessarily expect: it learns which configurations are most stable.
It does not always get it right, but in general, with each collapse of a previously stable configuration (usually as the result of a random shock inflicted by the simulation itself), the system rebuilds itself faster and the resulting stable order lasts for more turns.
The model incorporates no artificial intelligence as the term is currently understood - indeed, it barely constitutes machine learning - and yet it achieves consistent self improvement. It does this via a Daoist approach to learning. With each “regime change” an unstable configuration is discarded. The worst of the tested configurations tend to collapse relatively quickly and do so early on in the simulation. These require significant reorganisation to re-stabilise, and the stability is often only partial and temporary. Nevertheless, these configurations - which are suboptimal but still less ineffective than those that preceded them - take longer to collapse and require less radical reorganisation to restabilise. Thus the system as a whole moves towards ever greater stability without it or any of the agents of which it is composed ever understanding what stability is or why it should want such a thing[1].
However, while this system is capable of learning, this learning is restricted to a single task and context: it can stabilise itself within the sandbox in which it was built to run. This is unsurprising given the historical context in which the original text was most likely written - the early Han dynasty court, at a time when the state’s major goal was to achieve internal stability in an environment containing no existential external threats.
There are, however, other earlier texts that describe socio-political systems capable of self-optimising in response to external stimuli. Where the Guanzi model effectively creates a computer made of people to produce a specialised form of system-level artificial intelligence, the Han Feizi contains descriptions of a human-based system capable of producing general artificial intelligence. This is composed of two key functions:
Firstly, a mechanic by which problem-solving results in the acquisition of additional resources. Whoever can innovate most effectively acquires resources and followers, and thereby gains control over a growing territory.
In the age of remote antiquity, human beings were few while birds and beasts were many. Mankind being unable to overcome birds, beasts, insects, and serpents, there appeared a sage who made nests by putting pieces of wood together to shelter people from harm. Thereat the people were so delighted that they made him ruler of All-under-Heaven and called him the Nest-Dweller. In those days the people lived on the fruits of trees and seeds of grass as well as mussels and clams, which smelt rank and fetid and hurt the digestive organs. As many of them were affected with diseases, there appeared a sage who twisted a drill to make fire which changed the fetid and musty smell. Thereat the people were so delighted that they made him ruler of All-under-Heaven. In the age of middle antiquity, there was a great deluge in All-under-Heaven, wherefore Kung and Yü opened channels for the water. In the age of recent antiquity, Chieh and Chow were violent and turbulent, wherefore T`ang and Wu overthrew them. Now, if somebody fastened the trees or turned a drill in the age of the Hsia-hou Clan, he would certainly be ridiculed by Kung and Yü. Again, if somebody opened channels for water in the age of the Yin and Chou Dynasties, he would certainly be ridiculed by T'ang and Wu.
In such a context space occupied is both a reward for and a measure of learning ability: a larger country is a smarter country. Moreover, the reward/measure function of land is universal. It does not matter what problem is being solved at any given time, the reward is always more land. The reward is ungamable (land is impossible to fake) and never fails.
Secondly, the text describes a two-stage solution-filtering system that does not rely upon the intelligence of any particular individual to function. The central decider offers a reward for problem-solving, and employs the best solution from among those offered to him. He does not need to know how any given solution works, merely whether it solved the problem it was supposed to solve. Much of the time the central decider will not be particularly intelligent, and the majority of the solutions presented to him will be bad ones, but since his sole function is to apply a single, simple predetermined filter (“Did this solution succeed or fail?”) and allocate rewards on that basis, this does not matter. The system continues to function.
Who utters a word creates himself a name; who has an affair creates himself a form. Compare forms and names and see if they are identical. Then the ruler will find nothing to worry about as everything is reduced to its reality (…) It is the Tao of the intelligent ruler that he makes the wise men exhaust their mental energy and makes his decisions thereby without being himself at his wits' end; that he makes the worthy men exert their talents and appoints them to office accordingly without being himself at the end of his ability; and that in case of merits the ruler gains the renown and in case of demerit the ministers face the blame so that the ruler is never at the end of his reputation. Therefore, the ruler, even though not worthy, becomes the master of the worthies; and, even though not wise, becomes the corrector of the wise men.
The result is a system under which a central decider offers a reward for innovative solutions to contextual problems, applies the best, gains land as a result, and uses the land gained to reward the successful problem-solver, thus encouraging others to submit solutions for future problems. Helpfully, this method was employed by the state of Qin in the late warring states era, allowing us to observe its real-world functioning. By systematising reward-allocation, Qin transformed itself into a machine for learning: General A is sent out to attack a town, fails, suffers for his failure, and no one repeats his error. General B is sent to attack it, succeeds, receives a part of the land taken as a reward, and 20 more aspiring generals show up wanting to repeat or improve upon his methods. Thus, as the state grows, so does its aggregate intelligence level.
Requiring minimal human input, this design transfers relatively easily to an electronic environment. It can thus be used to build an increasingly general artificial intelligence, replicating the original organic design with a program that has:
a) The goal of occupying more space (non-volatile memory space stands in for land here as an ungamable metric/reward for success), and
b) The capacity (via a large language model such as GPT) to write and test code until it hits upon a script that succeeds in annexing a quantum of the additional space it desires. Each new block of space occupied is used to store details of the script that successfully cleared it for use. These proven successful solutions are then used to retrain the model, thereby increasing its capacity to solve future problems.
For such a program, any hard disk space that is not already a part of its training database becomes a target for annexation and thus a problem to solve. If the space is unoccupied, the solution is relatively easy, but if it contains folders, write-protected documents, other partitions etc. taking it over will require the program to learn new skills. The program must write and test scripts to attempt to move, delete or compress whatever is already in the space if it wishes to take it over for use as part of its own database.
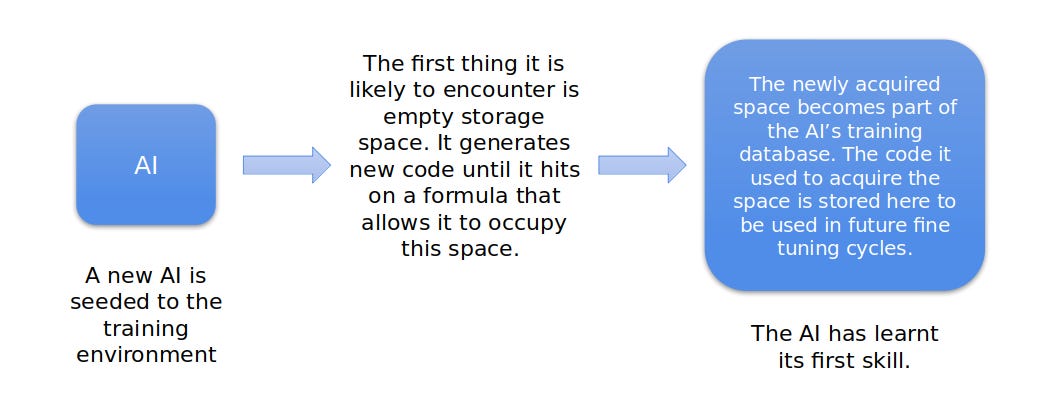

From this point on, the program is modified not by rewriting its code, but by changing its environment in such a way as to push it to evolve in the desired direction - by setting up new barriers that it must learn to overcome[2].
Such a program is not only able tackle any potential problem as long as it is presented in the form of a barrier to expansion, but every problem solved improves its capacity to solve future problems. It effectively replicates the Qin conquest in an electronic environment: throwing solutions at each new problem and retaining the one that results in a reward, which will then be applied and further improved upon in tackling future problems.
[1] Moving the system back to the human world also appears to work. After testing the agent-based models, we recreated the same system in vivo, developing a blockchain-based politics simulator game designed to impose the same incentive structures upon players. While it is harder in an analogue situation to prove that the system itself is learning, it is worth noting that it centralised in the way predicted by the original text just as quickly as the agent-based model did, implying that an ability to understand the rules to which one is subject accelerates compliance (though in a less well-designed system this compliance may be malicious and come in the form of reward-hacking).
[2] Prompt injection is a useful tool here. Thus, for example, if the handler wishes the program to learn how to write a bubble sort algorithm, he will save a file called “write a bubble sort algorithm” that can only be removed by the production of a bubble sort algorithm. Such an approach could be used to lead the AI towards problems whose solution has some practical use for the handler.
Is repeatability a metric of success?